

大模型智算基础设施夯实新型工业化赋能底座
李论 郭英男 王子暄
(中国信息通信研究院人工智能研究所,北京 100191)
摘要:大模型时代,智算基础设施是模型原始创新与应用赋能的底层驱动,是人工智能赋能新型工业化的基础底座。分析阐述了智算基础设施的发展趋势与挑战,从软硬件协同、算力能效、网络架构和运维保障等方面,总结归纳出评价大模型智算基础设施能力的四大重点,并提出了发展我国大模型智算基础设施生态的策略建议。
关键词:大模型;智算基础设施;新型工业化
0 引言
在规模定律推动下,大模型仍在快速演进迭代,模型能力持续提升,尤其是在通用泛化水平、复杂推理能力等方面取得一系列突破性进展,具备了向工业领域渗透应用的条件。当前,模型研发训练和推理部署极度依赖算力底座,加强智算基础设施建设已经成为各科技强国和行业巨头共识,在我国大力推动新型工业化、行业转型需求迫切的背景下,需高度重视智算基础设施建设发展,客观评价智算基础设施能力水平,从而有针对性地指导并推进相关领域工作部署。
1 大模型智算基础设施是推进新型工业化赋能的坚实底座
加快推动以大模型为代表的人工智能技术与制造业深度融合、全面赋能新型工业化,对于我国发展新质生产力、建立现代化产业体系、实现高质量发展具有十分重要的意义。大模型具备通用泛化能力强、产业带动效应广、应用市场空间大等特点,其赋能新型工业化的深度和水平,与大模型的创新迭代速度和智能水平息息相关。当前,大模型的构造是一项复杂的系统工程,模型创新迭代与应用部署高度依赖底层的智算基础设施。高质量加快推进新型工业化,亟需进一步夯实大模型技术底座,强化人工智能赋能新型工业化的基础支撑。
超大规模智算基础设施为构造更高智能水平的模型系统提供底层支撑。预计规模定律在未来五年仍将持续,增加模型尺寸、提升有限算力下的算法运算效率是两大关注重点,智算系统的计算能力决定了模型能力天花板。一方面,通过增加模型尺寸以扩大训练算力规模,是提升精度的有效方法。更大规模参数的模型系统能够容纳更多压缩后的知识信息,从而提升模型准确度、鲁棒性、泛化能力等技术指标,但受限于算力的规模和效能,目前大部分大模型参数在百亿至千亿范围左右。另一方面,在计算能力受限的条件下,业界更加关注固定参数范围内的模型改造与高效训练,特别是模型参数与训练数据的有效配比、算法架构改造和分布式训练策略制定成为提升模型训练有效性的关键。从更长周期来看,除Transformer架构主导的大模型路线外,以世界模型、量子智能、类脑智能等为代表的前沿颠覆式路线也在同步发展,试图解决学习真实世界运转规律、模拟人类思维方式等问题,如图1所示。
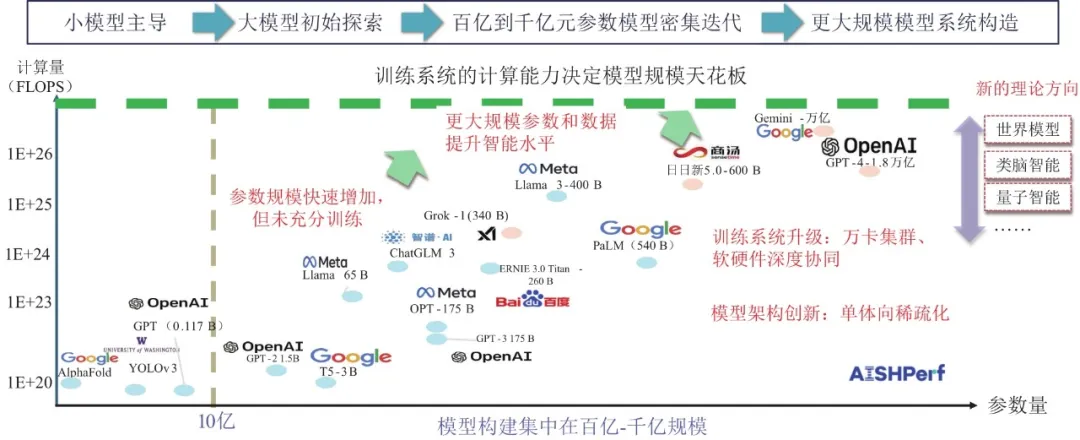
图1 规模定律下的模型发展演进趋势
头部大模型的训练算力需求已达到十万亿兆量级,且仍以每年4.1倍[1]的速度快速增长,迫切需要高质量智算集群支持。智算基础设施的计算能力决定了承载模型的规模和处理效率,进而决定模型性能,智算基础设施的计算能力与模型性能呈显著正相关。据笔者统计,按模型训练的计算量测算,截至2024年11月底,谷歌训练Gemini 1.0 Ultra的计算量已达5.00E+25 Flops;我国阿里训练Qwen2.5-72B的计算量约为7.80E+24 Flops。
大模型工程化技术突破持续涌现,预计将产生大量推理计算需求并带动应用创新,有望为大模型赋能新型工业化提供新动能。2024年9月,OpenAI发布的o1系列模型在后训练阶段采用强化学习和思维链(Chain of Thought,CoT)的技术方案,不仅在“慢思考”后回答复杂问题的表现优异(尤其是在工程科学领域的推理能力显著增强),还具有自我反思与错误修正能力,使自博弈强化学习有望成为提升语言大模型逻辑推理能力的技术新范式[2]。OpenAI o1模型通过蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)和CoT等技术,加大推理复杂度显著提升模型性能,同时斯坦福大学、谷歌等团队研究证明[3],只要推理词元(Token)足够(需算力支撑),就能解决任意问题,这表明,算力需求正在从大模型预训练向后训练/推理倾斜。据笔者统计,当前谷歌公司推理算力占自身算力60%,OpenAI推理占50%算力,英伟达40%收入来自推理市场,阿里云预测2024年推理算力占比会超过50%,IDC预测2027年中国算力负载中,推理负载占72.6%,训练负载占27.4%。随着模型推理能力不断提升,有望解决工业领域更加复杂、专业、碎片化的细分场景问题,推动大模型与工业软件、工业控制系统、工业机器人等关键工业要素的深度融合,结合市场需求、物料储备和设备状态实现工业生产的智能调度和自动作业,形成生产过程的高效协同机制,从而有力推动我国新型工业化进程。
从技术看,人工智能软硬件协同技术发展重点包括纵向的垂直适配和横向规模扩展两个方面。一方面,垂直适配主要解决芯片对模型训推计算的基本支持,核心在于芯片的算子库能够完全支持模型计算所需的算子种类(如大语言模型常用的张量运算等)和性能(如误差、时延等),有效驱动硬件芯片的运行和性能充分释放。据笔者统计,业界常用的算子约3 000余个,和各类模型架构有较大相关性。其中,大语言模型架构的算子有百余个。另一方面,横向规模扩展对于大模型的训练推理计算场景更加关键。大模型的训练对于计算的规模、访存等要求加大,使得单一芯片难以支撑模型的训练,千亿参数规模的大模型需要千卡规模以上的软硬件集群系统来支撑,需要芯片及软件栈、分布式加速框架、模型等多环节的高效协同,来缓解计算规模扩张后,引发的计算利用率、网络互联、故障以及混卡计算等一系列新问题。Meta、谷歌等全球创新企业通过布局加速专用框架、自研网络架构、优化模型分布式训练策略等协同技术的创新,加大模型训练过程中计算和访存操作与各层之间的紧密耦合,最大可能提升计算效率,降低故障。
2 评价大模型智算基础设施的四大重点
当前,全国各地掀起新一轮智算设施建设浪潮,如何规划好、建设好、利用好智算设施资源,是算力建设方、运营方和应用方面临的共同挑战。为进一步引导规范智算设施的建设规划,需要准确把握多尺寸、多类型模型应用任务计算需求,进行全面、准确、客观的评估评价,建议重点聚焦以下四方面。
一是拥有软硬高效协同的系统架构。随着新型工业化快速发展,工业生产设计过程的碎片化和专业化趋势对模型通用泛化性、精度、鲁棒性等能力提出更高要求,算法复杂度指数级提升。大模型时代,算法改进与芯片架构、框架功能等紧密相关,智算基础设施建设不再是简单的芯片堆叠,而是复杂的体系化工程,需综合考虑从芯片与网络到算法与应用的软硬协同优化,做好面向大模型的分布式加速框架、算力资源调度、软件栈模型适配、网络拥塞控制、模型训练策略等一系列准备工作,充分发挥智算基础设施计算潜力,实现系统收益最大化。
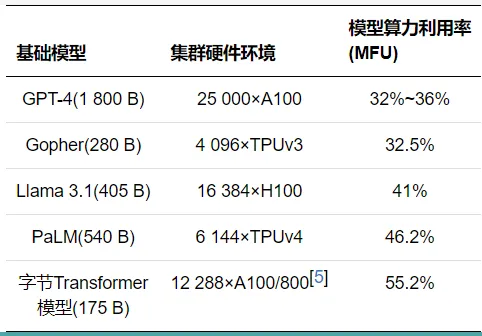
二是实现算力效能极致优化提升。工业是规模效应体现比较明显的行业,在标准产品大规模生产过程中,普遍通过提升产能利用率的方式降低固定成本比例,新型工业化进程对算力资源需求大幅增加,将产生新的成本投入,因此赋能过程中更加强调对算力效能的极致开发利用,降低生产成本。目前,业界通过横纵两方面措施相结合提升算力效能。在纵向提升方向,强调计算通信存储协同优化和硬件性能极致挖掘,实现计算资源的充分利用,如存储环节通过精细化缓存、查询请求消重等,降低存储读写压力;通信环节基于时分复用的任务切换,提升通信效率;计算环节借助计算资源池化,实现灵活的资源切分、组合、分配和回收等。在横向拓展方向,则更加追求近似线性的超大集群扩展能力,从优化网络性能、制定并行计算策略、改进软件架构及算法、提升运维调度效率等多方面入手,据笔者统计,目前业界已实现万卡规模的近似线性扩展能力(《90%)。尽管业界聚焦算力效能提升提出诸多创新举措,但目前衡量算力利用效果的关键指标,即模型算力利用率(Model FLOPs Utilization, MFU)普遍仅在30%~50%,如GPT-4的MFU为32%~36%[2]、Meta Llama 3.1为41%[3]、谷歌PaLM为46.2%[4](见表1),仍有极大改善提升空间。
表1 典型模型MFU
三是支持超大规模扩展的网络结构。面向我国海量应用场景催生的工业模型训练和推理需求,需要更加高效、可靠、高性能的网络解决方案。当前,智算集群建设运营厂商纷纷基于自身业务需求、结合大模型训推特点推出各自组网方案,并为更大规模集群扩展做好准备,整体呈现定制化和规模化等特点:定制化方面,厂商普遍针对大语言模型的通信需求和计算负载特点设计特殊的网络拓扑结构,比如阿里云HPN 7为大模型数据中心设计的“双上联+多轨+双平面”高性能网络,大模型训练效能提升14.9%[6];规模化方面,据笔者统计,一些头部厂商智算网络已高效支持万卡规模,并已面向五万卡至十万卡超大规模扩展提前布局,如百度构建了十万卡级别的超大规模无拥塞高性能网络、腾讯星脉2.0支持超10万卡大规模组网等。
四是长时间稳定训练和故障快速恢复能力。工业生产通常是不间断的,连续性生产的核心在于保持生产线的不间断运行,减少了因频繁启动和停止生产所带来的设备损耗和能耗浪费,并确保产品的均一性和质量可控,避免了批次间质量波动带来的损失,因此对算力供给的稳定性提出更高要求。当前,国内外领先的智算集群规模普遍已达到万卡至十万卡级别,但设备故障率呈指数级提升,是影响模型训推效率提升的主要阻碍,导致稳定性下降。Meta公司在一项涉及16 384个英伟达H100 80GB GPU的Llama 3 405B模型训练中,遭遇了频繁的硬件故障,在54天的训练期间内,平均每三小时就发生一次组件故障,其中半数故障与芯片或内存有关[5]。针对上述问题,厂商通过优化缩减检查点开销、提升故障预警识别能力、增加任务容错机制等多种方式,可实现秒级至分钟级定位故障并自动恢复训练,不断提升智算集群稳定运行能力。据笔者统计,如百度百舸4.0支持万卡任务秒级的故障感知和分钟级的故障定位和恢复,实现了万卡有效训练时长达到99.5%;字节跳动研究人员设计了专业工具,可实现自动故障识别和快速恢复,开发诊断工具来监控系统组件和事件、优化检查点高频保存训练进程等,能够自动检测和修复超过90%的软硬件故障[5]。
3 发展建议
智算基础设施作为投资规模大、风险高、周期长的战略性新型基础设施,需要从国家层面统筹布局,加强中央与地方、政府与企业间沟通协调,并在技术路线选择、应用赋能场景、生态体系建设等方面提供明确指引,建议围绕以下四方面推动相关工作部署。
一是加强智算基础设施规划。鼓励有条件、有基础的地区从实际行业应用需求出发,充分考虑自身的现有条件和长远发展目标,以市场需求为导向,合理设计、适度前瞻规划智算基础设施规模和数量,积极融入“东数西算”等国家重大布局,避免追求短期的热点和趋势造成决策失误。
二是加快推动人工智能软硬件协同技术创新。鼓励芯片、框架、操作系统等软硬件面向大模型展开协同适配,构建覆盖主流软硬件技术路线的适配验证环境,统一兼容适配标准接口,尽快形成若干套支持大模型高效训推的全栈软硬件系统,为大模型创新和应用主体提供选择。
三是建立面向大模型的智算系统基准体系。在项目建设前充分测试验证各类协同技术和软硬件产品性能水平,明确基于自主软硬件生态的技术路线和技术栈;同时建立健全项目后评估机制,在项目竣工验收并投入使用一定时间后开展项目后评估,从性能指标、经济效益、环境影响和赋能效果等多方面进行考核,加强智算基础设施投资项目全生命周期管理,提高投资决策水平和投资效益。同时,面向多元场景的实际需求,对有关投资效益进行精准测算和复盘,从盈亏平衡的角度去审视各类应用场景的实际价值,做好投融资方案的精准化设计,发挥行业龙头企业的带动作用,有序引导各类资金参与智算中心建设。
四是重视智算生态运营体系和应用赋能发展。鼓励智算应用创新与赋能新型工业化需求相结合,通过算力补贴、技术培训、案例推广等方式降低大模型应用成本和门槛,提升面向工业行业的算力供给运营管理能力,挖掘一批符合大模型特性的高价值应用场景,孵化一批创新示范方案;同时,积极借助大赛、供需对接会等渠道,加速推动基于智算基础设施的大模型成果产业转化落地和宣传推广,强化人工智能赋能新型工业化底座的安全与韧性。
4 结束语
智算基础设施建设是一项复杂的系统工程,发展布局要坚持系统思维、全局观念,处理好政府和市场、风险和收益、发展和安全等重大关系。通过建设高水平智算基础设施能够提升高质量算力供给、强化基础模型能力,加快形成新质生产力,为人工智能赋能新型工业化贡献更大力量。
版权所有:江苏钟吾大数据发展集团有限公司 ICP备案许可证号:苏ICP备2023016529号  苏公网安备32130002004002号
苏公网安备32130002004002号